Проект был разработан в 2025 году в рамках форума Всероссийской олимпиады студентов «Я — профессионал» по искусственному интеллекту, математике и физике от МТС AI и МФТИ для решения актуальной проблемы — ручной классификации сложных случаев выпускных данных книжных изданий.
По результатам форума занял 1-е место.
Библиотеки, архивы, издательства и индивидуальные пользователи (студенты, преподаватели, научные сотрудники) тратят значительное время на определение типов страниц (обложка, титул, оборот титула, колофон), что снижает скорость каталогизации и повышает риск ошибок.
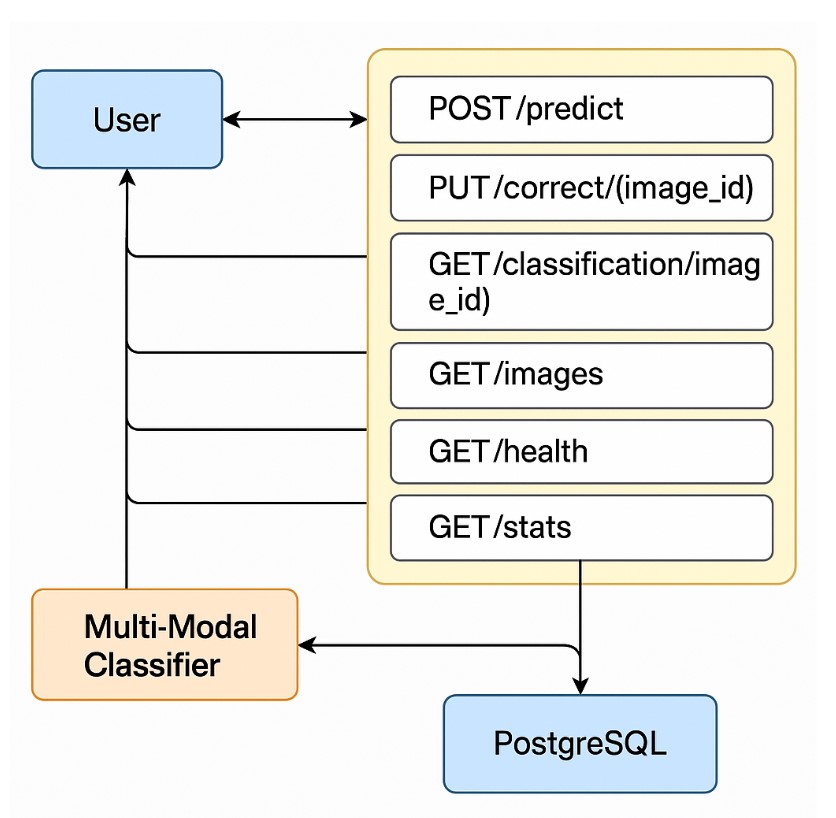
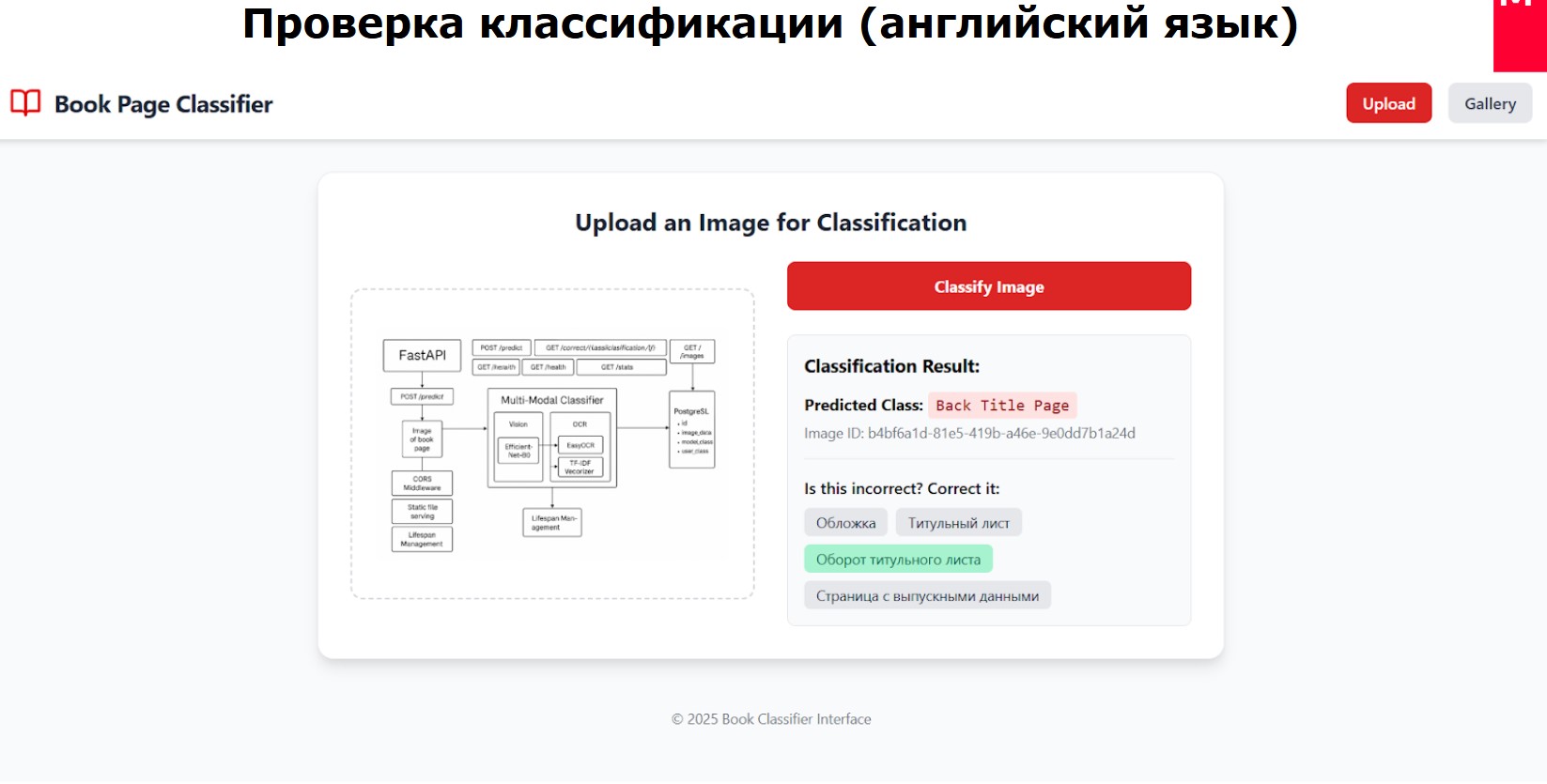
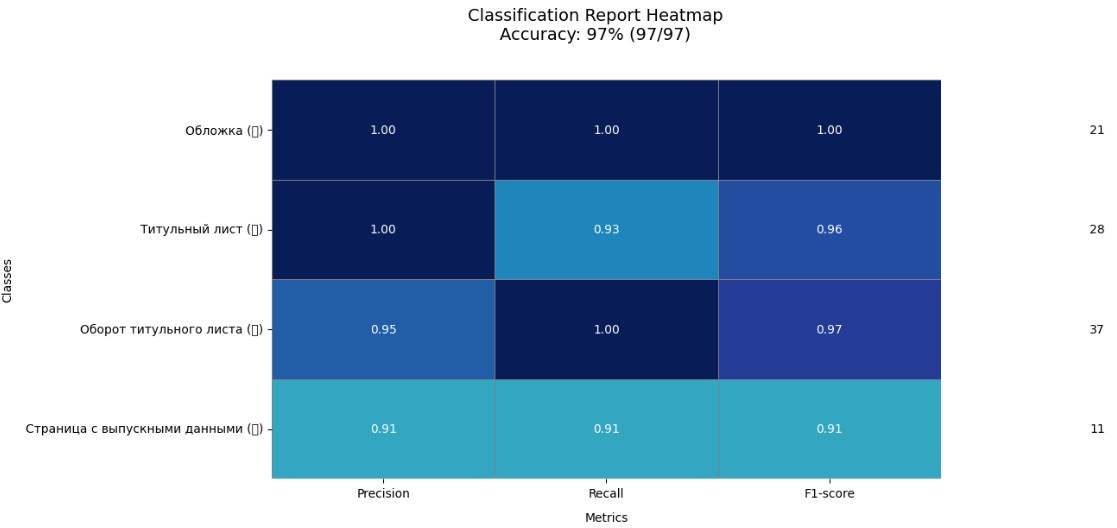
Целью проекта стало создание автоматизированной системы распознавания типов страниц книжных изданий с использованием OCR и компьютерного зрения. В результате работы была разработана гибридная нейросетевая модель MultiModalClassifier, объединяющая CNN (EfficientNet-B0) для визуальных признаков и MLP для текстовых признаков, извлечённых через EasyOCR и TF-IDF. Точность модели на валидационном наборе достигла 97%.
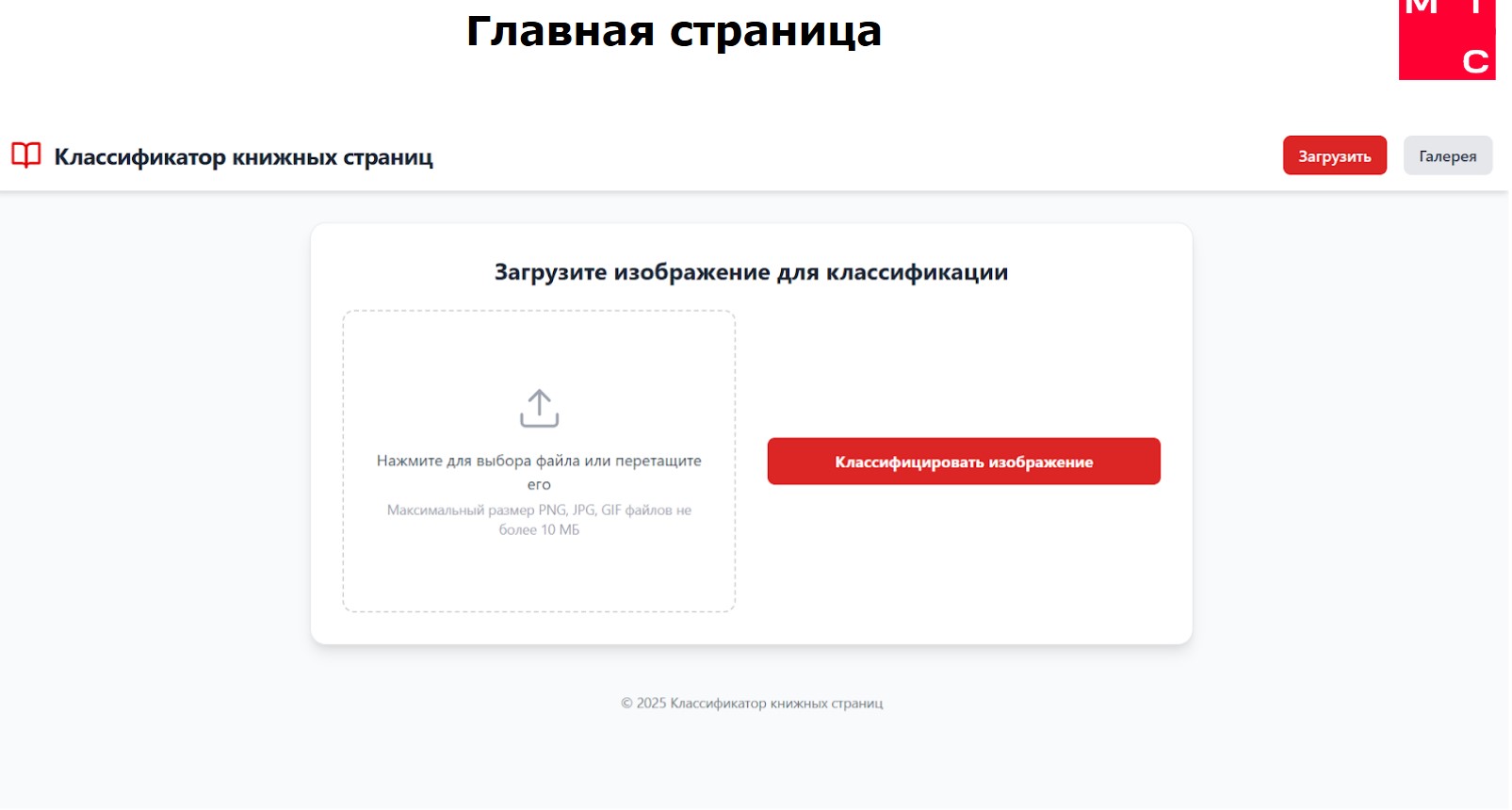
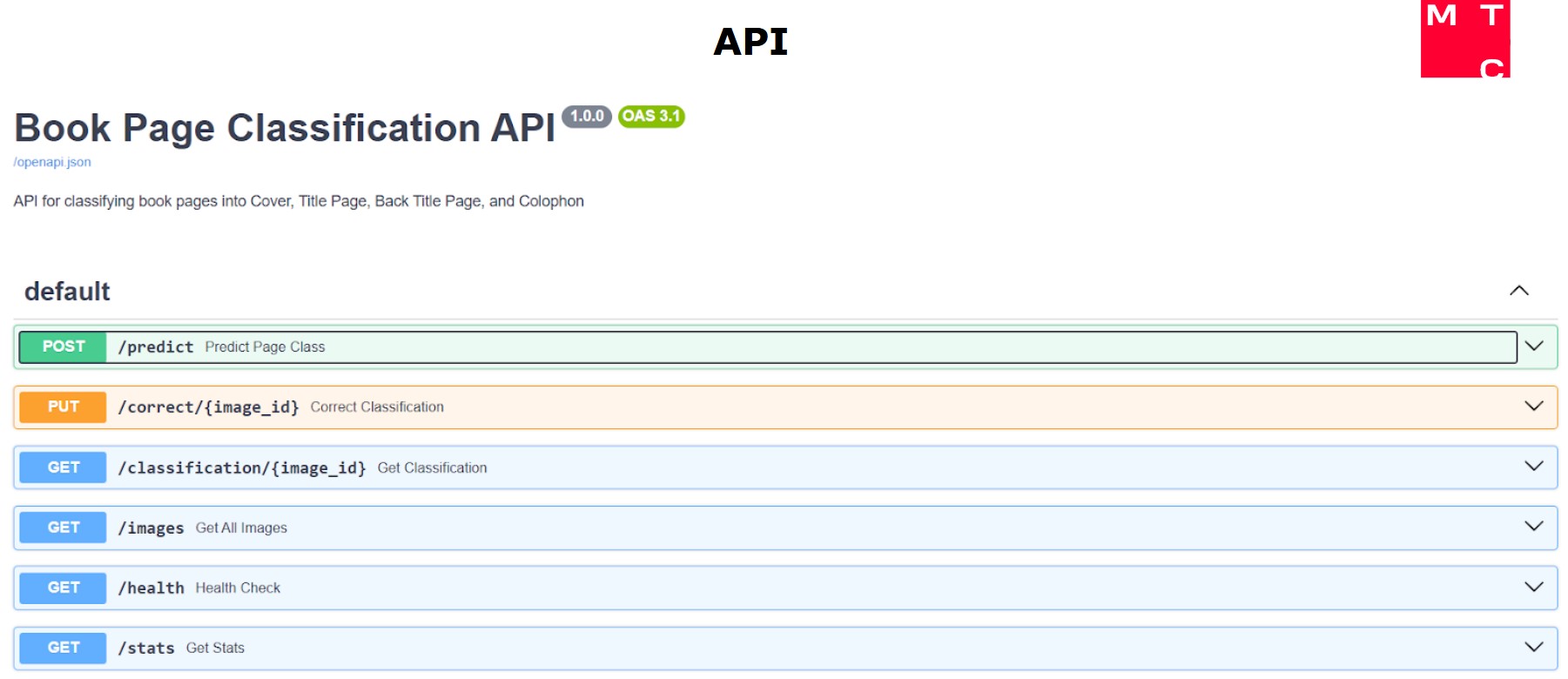
Ошибки классификации минимизированы за счёт комбинирования визуального и текстового анализа, а также возможности ручной корректировки результатов через веб-интерфейс. Система поддерживает загрузку изображений (PDF/JPEG), автоматическое распознавание, редактирование типов страниц и экспорт данных. Для организаций предусмотрено API для интеграции с существующими системами.